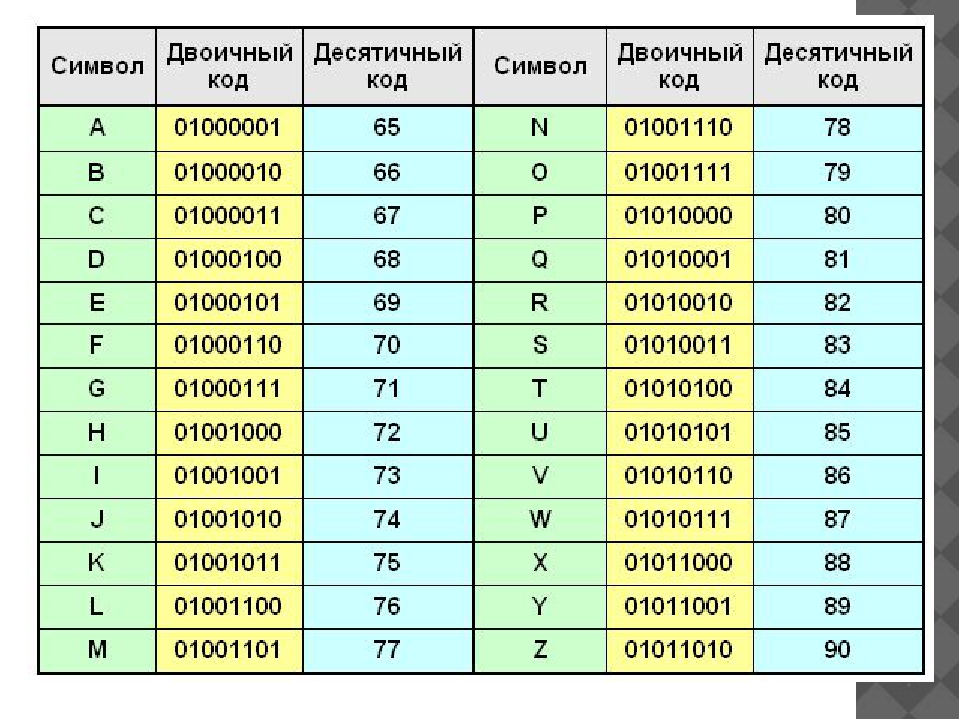
Строки с переменной в качестве длины могут содержать столько символов, сколько необходимо. Как правило, длина строки указывается одним из следующих двух способов: явное содержание длины строки или использование сигнального символа. Мы можем явно хранить длину строки, используя символ счетчика местоположения $, который представляет текущее значение счетчика местоположения строки.
Немного информации…
Прежде чем перейти к листингу сегодняшней темы, все же стоит отметить: как таковых массивов в Assembler нет, есть нечто похожее. И это нам, программистам, удобнее всего называть как массив. Обычно понятия массивов используют в таких языках как C++, Си и т.д.
В наших следующих статьях мы будем разбирать ассемблеровские вставки для C++, а сегодня мы просто ознакомимся с последовательностью символов.
Источник: http://codetown.ru/assembler/massivy/
Строки в Ассемблере
Строки с переменной в качестве длины могут содержать столько символов, сколько необходимо. Как правило, длина строки указывается одним из следующих двух способов:
явное содержание длины строки;
использование сигнального символа.
Мы можем явно хранить длину строки, используя символ счетчика местоположения $, который предоставляет текущее значение счетчика местоположения строки. Например:
|
msg db ‘Hello, world!’,0xa ; наша строка len equ $—msg ; длина нашей строки |
Символ $ указывает на byte после последнего символа строковой переменной msg. Следовательно, $ — msg указывает на длину строки. Мы также можем написать:
|
msgdb‘Hello, world!’,0xa ; наша строка lenequ13 ; длина нашей строки |
В качестве альтернативы мы можем хранить строки с завершающим сигнальным символом. Сигнальным символом является специальный символ, который не должен находиться внутри строки. Например:
|
messageDB‘I am loving it!’,0 |
Источник: http://ravesli.com/assembler-stroki/
Мои прошлые статьи по ассемблеру
Ну не прошло и недели и мы снова говорим об ассемблере. Как вы уже поняли, язык ассемблера очень детальный и в этом его сложность. Вместо переменных приходится работать с ячейками памяти и регистрами процессора. Это напрягает, потому что одно действие на языке высокого уровня может на ассемблере записываться десятками команд. И, конечно, время разработки программы на ассемблере довольно велико по сравнению с другими языками. Конечно, можно использовать библиотеки языков высокого уровня (например C), что ускоряет разработку и мы об этом в будущем будем говорить.
Источник: http://zen.yandex.ru/media/id/5f04c4d28b9cee73d889add0/programmirovanie-na-assemblere-dlia-linux-konsolnyi-vvodvyvod-statia-2-5f2fc7dee546a33943428742
Строковые инструкции
Каждая строковая инструкция может требовать исходного операнда и операнда назначения. Для 32-битных сегментов строковые инструкции используют регистры ESI и EDI, чтобы указать на операнды источника и назначения, соответственно.
Однако для 16-битных сегментов, чтобы указать на источник и место назначения, используются другие регистры: SI и DI.
Существует 5 основных инструкций для работы со строками в Ассемблере:
MOVS — эта инструкция перемещает 1 byte, word или doubleword данных из одной ячейки памяти в другую;
LODS — эта инструкция загружается из памяти. Если операндом является значение типа byte, то оно загружается в регистр AL, если типа word — загружается в регистр AX, если типа doubleword — загружается в регистр EAX;
STOS — эта инструкция сохраняет данные из регистра (AL, AX или EAX) в память;
CMPS — эта инструкция сравнивает два элемента данных в памяти. Данные могут быть размера byte, word или doubleword;
SCAS — эта инструкция сравнивает содержимое регистра (AL, AX или EAX) с содержимым элемента, находящегося в памяти.
Каждая из вышеприведенных инструкций имеет версии byte, word или doubleword, а строковые инструкции могут повторяться с использованием префикса повторения.
Эти инструкции используют пары регистров ES:DI и DS:SI, где регистры DI и SI содержат валидные адреса смещения, которые относятся к байтам, хранящимся в памяти. SI обычно ассоциируется с DS (сегмент данных), а DI всегда ассоциируется с ES (дополнительный сегмент).
Регистры DS:SI (или ESI) и ES:DI (или EDI) указывают на операнды источника и назначения, соответственно. Предполагается, что операндом-источником является DS:SI (или ESI), а операндом назначения — место в памяти, на которое указывает пара ES:DI (или EDI).
Для 16-битных адресов используются регистры SI и DI, а для 32-битных адресов используются регистры ESI и EDI.
В следующей таблице представлены различные версии строковых инструкций и предполагаемое место операндов:
| Основная инструкция | Операнды в: | Операция byte | Операция word | Операция doubleword |
| MOVS | ES:DI, DS:SI | MOVSB | MOVSW | MOVSD |
| LODS | AX, DS:SI | LODSB | LODSW | LODSD |
| STOS | ES:DI, AX | STOSB | STOSW | STOSD |
| CMPS | DS:SI, ES:DI | CMPSB | CMPSW | CMPSD |
| SCAS | ES:DI, AX | SCASB | SCASW | SCASD |
Источник: http://ravesli.com/assembler-stroki/
Инструкция MOVS
Инструкция MOVS используется для копирования элемента данных (byte, word или doubleword) из исходной строки в строку назначения. Исходная строка указывается с помощью DS:SI, а строка назначения указывается с помощью ES:DI.
Рассмотрим это на практике:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
section.text global_start ; должно быть объявлено для использования gcc _start: ; сообщаем линкеру входную точку movecx,len movesi,s1 movedi,s2 cld repmovsb movedx,20 ; длина сообщения movecx,s2 ; сообщение для вывода на экран movebx,1 ; файловый дескриптор (stdout) moveax,4 ; номер системного вызова (sys_write) int0x80 ; вызов ядра moveax,1 ; номер системного вызова (sys_exit) int0x80 ; вызов ядра section.data s1db‘Hello, world!’,0; первая строка lenequ$—s1 section.bss s2resb20 ; назначение |
Результат:
Hello, world!
Источник: http://ravesli.com/assembler-stroki/
Основная программа
Начнем:
.386 .model flat, stdcall option casemap:none include ..INCLUDEuser32.inc include ..INCLUDEkernel32.inc includelib ..LIBkernel32.lib includelib ..LIBuser32.lib BSIZE equ 15
Те, кто уже не первую статью читают, знают, что все эти строки нужны, так как мы работаем на masm32, а также подключаем стандартные библиотеки.
Идем дальше:
.data buf BYTE BSIZE dup(?) stdout DWORD ? cWritten DWORD ?CRLF WORD ?first BYTE » CodeTown.ru — practical examples for programming!» second BYTE » Join us!»
В разделе переменные мы объявляем уже знакомые нам переменные для вывода на экран(первые 3 строчки в разделе data).
Далее идет переменная CRLF, она нам понадобится для перевода строки. Как она работает вы увидите чуть дальше.
А вот затем идет объявления так называемых массивов (массивы first и second), в данном случае массивы у нас строковые, и каждый символ занимает 1 байт, об этом говорит запись BYTE после имени массивов. В кавычках мы записали некоторый текст. По сути так объявляются массивы, и ничего сложного в понимании нет.
Далее мы выведем на экран наши массивы:
.code start: invoke GetStdHandle, -11 mov stdout, eax mov esi, offset first ;берем адрес 1 элемента mov edi, offset second ; массивов для выводаinvoke WriteConsoleA, stdout, esi, 50, ADDR cWritten, 0mov CRLF, 0d0ahinvoke WriteConsoleA, stdout, ADDR CRLF, 2, ADDR cWritten,0 ; переводим каретку на новую строкуinvoke WriteConsoleA, stdout, edi, 10, ADDR cWritten, 0invoke ExitProcess, 0 end start
Вывод осуществляется практически как и в предыдущей статье, за исключением одного: команда offset, ранее нам незнакомая, берет адрес 1 символа в массиве, и затем, мы записываем его в соответствующий регистр, это нужно чтобы при выводе мы могли указать адрес массива.
В функции WriteConsoleA записываем регистр, который содержит этот адрес, а затем записываем число, сколько символов хотим вывести, в данном примере для 1 массива это 50, а для второго 10.
И еще кое что: вы, наверное, заметили, что мы трижды использовали функцию вывода. Так вот, во 2 функции мы как раз используем переменную CRLF, которую по сути и выводим. Предварительно в эту переменную мы записали 0d0ah, это говорит Assembler, что мы хотим перейти на новую строку.
Источник: http://codetown.ru/assembler/massivy/
Повторим запуск программы
После того как мы записали код, и сохранили его в файл с расширением .asm(у меня это sixth.asm), посмотрим как он сработал:
Открываем командную строку, переходим в папку BIN(напомню, что файл нужно поместить туда, где хранится файл запуска amake.bat) с помощью команды cd BIN.
Далее прописываем amake.bat sixth(вы, естественно, напишите свое имя файла). А затем, запускаем файл sixth.exe
И вот, что должно выйти:

Если вы не совсем поняли как запускать файлы .asm, то советую вам посмотреть наши предыдущие статьи по Assembler, там более подробно рассказано об этом.
На этом мы закончим, ваши вопросы оставляйте в комментариях. У нас есть еще много того, о чем можно говорить, и в будущем примеры только усложнятся.
Скачать исходники
Источник: http://codetown.ru/assembler/massivy/
Инструкция CMPS
Инструкция CMPS сравнивает две строки. Эта инструкция сравнивает два элемента данных одного byte, word или doubleword, на которые указывают регистры DS:SI и ES:DI, и устанавливает соответствующие флаги. Вы также можете использовать инструкции прыжков вместе с этой инструкцией.
В следующем примере мы будем сравнивать две строки, используя инструкцию CMPS:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
section.text global_start ; должно быть объявлено для использования gcc _start: ; сообщаем линкеру входную точку movesi,s1 movedi,s2 movecx,lens2 cld repe cmpsb jecxz equal ; выполняем прыжок, когда ECX равен нулю ; Если не равно, то выполняем следующий код moveax,4 movebx,1 movecx,msg_neq movedx,len_neq int80h jmpexit equal: moveax,4 movebx,1 movecx,msg_eq movedx,len_eq int80h exit: moveax,1 movebx,0 int80h section.data s1db‘Hello, world!’,0 ; наша первая строка lens1equ$—s1 s2db‘Hello, there!’,0 ; наша вторая строка lens2equ$—s2 msg_eqdb‘Strings are equal!’,0xa len_eq equ$—msg_eq msg_neqdb‘Strings are not equal!’ len_neqequ$—msg_neq |
Результат:
Strings are not equal!
Источник: http://ravesli.com/assembler-stroki/
Инструкция SCAS
Инструкция SCAS используется для поиска определенного символа или набора символов в строке. Искомый элемент данных должен находиться в регистрах AL (для SCASB), AX (для SCASW) или EAX (для SCASD). Искомая строка должна находиться в памяти, и на нее должны указывать ES:DI (или EDI).
Рассмотрим использование инструкции SCAS на практике:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
section.text global_start ; должно быть объявлено для использования gcc _start: ; сообщаем линкеру входную точку movecx,len movedi,my_string moval,‘e’ cld repnescasb jefound; когда нашли ; Если не нашли, то выполняем следующее moveax,4 movebx,1 movecx,msg_notfound movedx,len_notfound int80h jmpexit found: moveax,4 movebx,1 movecx,msg_found movedx,len_found int80h exit: moveax,1 movebx,0 int80h section.data my_stringdb‘hello world’,0 lenequ$—my_string msg_founddb‘found!’,0xa len_foundequ$—msg_found msg_notfounddb‘not found!’ len_notfoundequ$—msg_notfound |
Результат:
found!
Источник: http://ravesli.com/assembler-stroki/
Префиксы повторения
Префикс REP, если он установлен перед строковой инструкцией (например, REP MOVSB), вызывает повторение инструкции на основе счетчика, размещенного в регистре CX. REP выполняет инструкцию, уменьшает CX на 1 и проверяет, равен ли CX нулю. Он повторяет обработку инструкций, пока CX не станет равным нулю.
Флаг направления (DF) определяет направление операции:
Используйте CLD (англ. «Clear Direction Flag» = «Сбросить флаг направления», DF = 0), чтобы выполнить операцию слева направо.
Используйте STD (англ. «Set Direction Flag» = «Установить флаг направления», DF = 1), чтобы выполнить операцию справа налево.
Префикс REP также имеет следующие вариации:
REP — это безусловное повторение, которое повторяет операцию, пока CX не станет равным нулю.
REPE или REPZ — это условное повторение, которое повторяет операцию до тех пор, пока нулевой флаг (ZF) указывает на равенство нулю результата (сам ZF установлен в единицу). Повторение останавливается, когда ZF указывает на неравенство результата нулю (ZF сброшен в ноль), или когда CX равен нулю.
REPNE или REPNZ — это также условное повторение, которое повторяет операцию до тех пор, пока нулевой флаг указывает на неравенство нулю результата. Повторение останавливается, когда ZF указывает на равенство нулю результата, или когда CX уменьшается до нуля.
Оценить статью:


(
13
оценок, среднее:
4,38
из 5)

Загрузка…
Источник: http://ravesli.com/assembler-stroki/