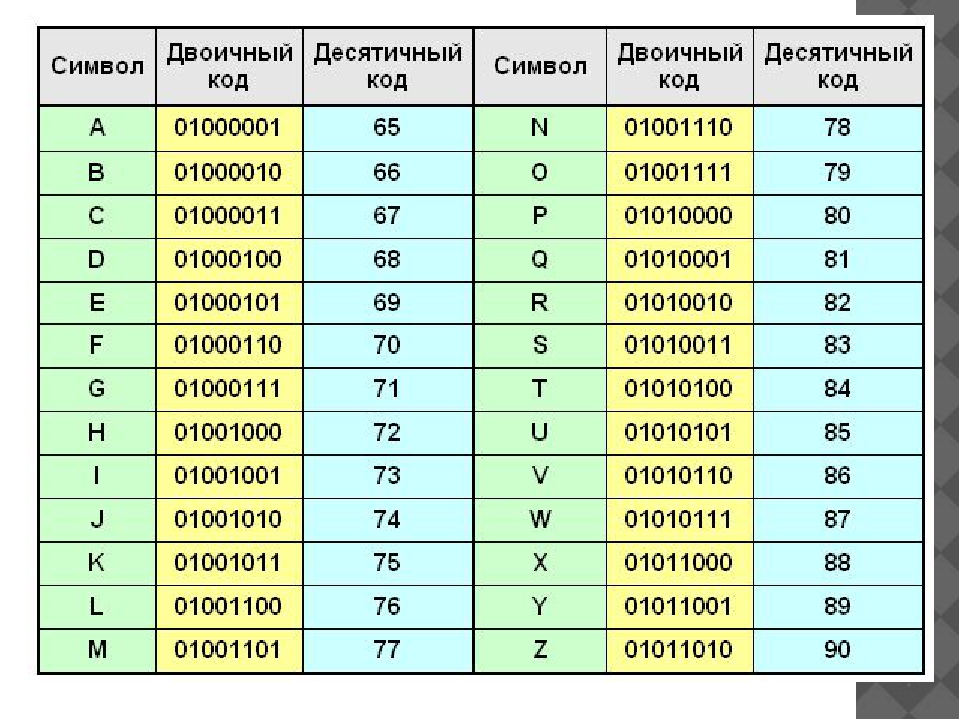
У этого термина существуют и другие значения, см. КОИ. КОИ 8 (код обмена информацией, 8 битов), KOI8 восьмибитовая ASCII совместимая кодовая страница, разработанная для кодирования букв кириллических алфавитов. Существует также семибитовая…
Как работает KOI8-R?
KOI8-R — восьмибитная кодовая страница, разработанная для кодирования букв кириллических алфавитов. Разработчики разместили символы русского алфавита таким образом, что позиции символов кириллицы соответствовали их фонетическим аналогам в английском алфавите в нижней части таблицы. И если в тексте, написанном в этой кодировке, убирать восьмой бит каждого символа, то получается текст, подобный транслиту латинскими буквами.
Такой код обмена информацией применялся в семидесятые годы на компьютерах серии ЕС ЭВМ, а с середины восьмидесятых его стали использовать в первых русифицированных версиях операционной системы UNIX.
Кодирование заключалось в том, что каждому символу присваивался уникальный код: от 00000000 до 11111111. Таким образом, человек различал символы по их начертанию, а компьютер — по их коду.

Источник: http://aif.ru/dontknows/file/chto_za_kodirovka_koi8-r_i_chto_ona_dala
KOI-7
Кодировка KOI-7 (KOИ-7, Код Обмена Информацией, 7-ми битный) позволяет кодировать 27 = 128 символов, из которых 32 буквы русского алфавита, 26 букв латинского алфавита, 10 цифр и 26 печатаемых символа, пробел, специальные символы и непечатаемые символы. Коды непечатаемых символов находятся в диапазоне 00-20 (с ними можно ознакомиться в разделе 7.1, в таблице ASCII).
Замечательным правилом, действующим в этой кодировке является весовой принцип кодирования латинских символов, для которого верно правило: Веса кодов букв латинского алфавита увеличиваются на единицу в алфавитном порядке, то есть:
Код последующего символа = Код предыдущего символа + 1, илиКод D = Код C + 1, и так далее…
Пользуясь этим правилом, можно легко располагать слова в алфавитном порядке, поскольку эта операция сводится к простому сравнению двоичных чисел, соответствующих кодам символов. Для русских символов этот принцип несправедлив.
Каждый символ в кодировке KOI-7 представлен восьмиразрядным двоичным числом (фактически, это один байт). Младшие 7 знакомест предназначены для кода самого символа, а самый старший бит называется разрядом контроля четности и очень часто используется для контроля ошибок, особенно при передаче данных. В этот разряд вписывают такое число (0 или 1), чтобы сумма единиц, содержащихся в коде данного символа, было четным.
|    Число    |    Символ    |    Число    |    Символ    |    Число    |    Символ    |    Число    |    Символ    |    Число    |    Символ    |    Число    |    Символ    |
|---|---|---|---|---|---|---|---|---|---|---|---|
|
20 |
пробел |
30 |
40 |
@ |
50 |
P |
60 |
Ю |
70 |
П |
|
|
21 |
! |
31 |
1 |
41 |
A |
51 |
Q |
61 |
А |
71 |
Я |
|
22 |
« |
32 |
2 |
42 |
B |
52 |
R |
62 |
Б |
72 |
Р |
|
23 |
# |
33 |
3 |
43 |
C |
53 |
S |
63 |
С |
73 |
С |
|
24 |
$ |
34 |
4 |
44 |
D |
54 |
T |
64 |
Д |
74 |
Т |
|
25 |
% |
35 |
5 |
45 |
E |
55 |
U |
65 |
Е |
75 |
У |
|
26 |
& |
36 |
6 |
46 |
F |
56 |
V |
66 |
Ф |
76 |
Ж |
|
27 |
‘ |
37 |
7 |
47 |
G |
57 |
W |
67 |
Г |
77 |
В |
|
28 |
( |
38 |
8 |
48 |
H |
58 |
X |
68 |
Х |
78 |
Ь |
|
29 |
) |
39 |
9 |
49 |
I |
59 |
Y |
69 |
И |
79 |
Ы |
|
2A |
* |
3A |
: |
4A |
J |
5A |
Z |
6A |
Й |
7A |
З |
|
2B |
+ |
3B |
; |
4B |
K |
5B |
[ |
6B |
К |
7B |
Ш |
|
2C |
, |
3C |
4C |
L |
5C |
6C |
Л |
7C |
Э |
||
|
2D |
— |
3D |
= |
4D |
M |
5D |
] |
6D |
М |
7D |
Щ |
|
2E |
. |
3E |
> |
4E |
N |
5E |
^ |
6E |
Н |
7E |
Ч |
|
2F |
/ |
3F |
? |
4F |
O |
5F |
Ъ |
6F |
О |
7F |
«забой» |
Источник: http://vestikinc.narod.ru/AB/1251koi8.htm
Кодировка KOI8-R (русская)
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
─ 2500 |
│ 2502 |
┌ 250C |
┐ 2510 |
└ 2514 |
┘ 2518 |
├ 251C |
┤ 2524 |
┬ 252C |
┴ 2534 |
┼ 253C |
▀ 2580 |
▄ 2584 |
█ 2588 |
▌ 258C |
▐ 2590 |
| 9. |
░ 2591 |
▒ 2592 |
▓ 2593 |
⌠ 2320 |
■ 25A0 |
∙ 2219 |
√ 221A |
≈ 2248 |
≤ 2264 |
≥ 2265 |
A0 |
⌡ 2321 |
° B0 |
² B2 |
· B7 |
÷ F7 |
| A. |
═ 2550 |
║ 2551 |
╒ 2552 |
ё 451 |
╓ 2553 |
╔ 2554 |
╕ 2555 |
╖ 2556 |
╗ 2557 |
╘ 2558 |
╙ 2559 |
╚ 255A |
╛ 255B |
╜ 255C |
╝ 255D |
╞ 255E |
| B. |
╟ 255F |
╠ 2560 |
╡ 2561 |
Ё 401 |
╢ 2562 |
╣ 2563 |
╤ 2564 |
╥ 2565 |
╦ 2566 |
╧ 2567 |
╨ 2568 |
╩ 2569 |
╪ 256A |
╫ 256B |
╬ 256C |
© A9 |
| C. |
ю 44E |
а 430 |
б 431 |
ц 446 |
д 434 |
е 435 |
ф 444 |
г 433 |
х 445 |
и 438 |
й 439 |
к 43A |
л 43B |
м 43C |
н 43D |
о 43E |
| D. |
п 43F |
я 44F |
р 440 |
с 441 |
т 442 |
у 443 |
ж 436 |
в 432 |
ь 44C |
ы 44B |
з 437 |
ш 448 |
э 44D |
щ 449 |
ч 447 |
ъ 44A |
| E. |
Ю 42E |
А 410 |
Б 411 |
Ц 426 |
Д 414 |
Е 415 |
Ф 424 |
Г 413 |
Х 425 |
И 418 |
Й 419 |
К 41A |
Л 41B |
М 41C |
Н 41D |
О 41E |
| F. |
П 41F |
Я 42F |
Р 420 |
С 421 |
Т 422 |
У 423 |
Ж 416 |
В 412 |
Ь 42C |
Ы 42B |
З 417 |
Ш 428 |
Э 42D |
Щ 429 |
Ч 427 |
Ъ 42A |
Источник: http://dic.academic.ru/dic.nsf/ruwiki/11979
ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки неблагозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую
ASCII
(American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания.Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы вроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:

Именно эти 128 символов из первоначального варианта ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд
расширенных кодировок ASCII
, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).Тут, наверное, стоит еще немного сказать о системах счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет собой двойку в степени, начиная с нулевой, и до двойки в седьмой:

Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получается 233 в десятичной системе счисления. Как видите, все очень просто.Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).Ну так вот, для
перевода двоичного числа в шестнадцатеричное
прибегают к следующему простому способу. Каждый байт информации разбивают на две части по четыре бита. Т.е. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.Причем в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Источник: http://javarush.ru/groups/posts/1418-kodirovka-teksta-ascii-windows-1251-cp866-koi8-r-i-junikod-utf-8-16-32—kak-ispravitjh-problemu
Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор +34
Программирование 
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Источник: http://itnan.ru/post.php?c=1&p=478636
Предпосылки Unicode
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 2
8
=256).
Первые 7 бит (128 символов 2
7
=128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:

Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Итак, закодируем строку «ok» (англ.) в кодировке ASCII. Символ «o» (англ.) имеет позицию 111 в десятичном виде и
6F
в шестнадцатиричном. Переведем это в двоичную систему —
01101111
. Символ «k» (англ.) — позиция 107 в десятеричной и
6B
в шестнадцатиричной, переводим в двоичную —
01101011
. Итого строка «ok» закодированная в ASCII будет выглядеть так —
01101111 01101011
. Процесс декодирования будет обратный. Берем по 8 бит, переводим их в 10-ичную кодировку, получаем номер символа, смотрим по таблице что это за символ.
Источник: http://itnan.ru/post.php?c=1&p=478636
Используется ли сейчас кодировка Чернова?
Нет. Она была актуальна для старых восьмибитных компьютеров, сейчас в основном используется Юникод в различных форматах.
Источник: http://aif.ru/dontknows/file/chto_za_kodirovka_koi8-r_i_chto_ona_dala
Win1251 (CP1251)
Кодировка Win1251 (CP1251, Code Page 1251, кодовая страница) сейчас является одной из наиболее распространенных в сети Интернет и персональных компьютерах (на которых установлена операционная система Windows. Все Windows приложения должны понимать эту кодировку без перевода.
Источник: http://vestikinc.narod.ru/AB/1251koi8.htm
Ссылки
- Сводка кириллических 8-битных кодировок
- RFC 1489
- RFC 2319
Источник: http://dic.academic.ru/dic.nsf/ruwiki/11979
СЕМЕЙСТВО КОДИРОВОК 8859
Восьмибитное семейство кодировок 8859, созданное International Standorts Organization, ISO, для наведения порядка в восьмибитных кодировках, расширило таблицу ASCII для латинских букв с диакритикой и лигатур (кодировка ISO 8859-1), славянских языков с латинским алфавитом, например, чешский, польский, венгерский, (ISO 8859-2), турецкого, мальтийского, эсперанто, галисийского языков (ISO 8859-3), кириллицы (ISO 8859-5), арабского (ISO 8859-6), греческого (ISO 8859-7), иврита (ISO 8859-8) и других языков. Кириллическая кодировка этого семейства не получила широкого распространения, зато стандарт ISO 8859-1 (так называемая Latin-1) стала стандартом для «расширенной» латиницы и содержит практически все символы западноевропейских языков. Так, многие шрифты для Windows соответствуют кодировке ISO 8859-1 начиная с позиции 160 до конца таблицы, а в диапазоне 128-159 содержат дополнительные символы (длинное тире или «торговая марка», например). Именно в этом семействе появилось понятие «кодовая страница» (набор из 256 символов для каждого определённого языка или группы языков). Крупным недостатком такого подхода является невозможность смешивания языков в одном документе и отсутствие представления для китайского и японского языков.
Оглавление Следующий раздел >>
Одесский национальный университет им. И.И. Мечникова
Кафедра компьютерных и информационных технологий
Все права защищены © 
Web-страница автора
Алексей Алешин

Источник: http://vestikinc.narod.ru/AB/1251koi8.htm