[решено] У меня есть 5 больших файлов XML , который я стремлюсь анализировать. Все они слишком велики для открытия в текстовом редакторе , поэтому я не зн
Примеры
Далее следуют примеры.
-
А. Массовый импорт XML-данных в виде двоичного байтового потока
-
Б. Массовый импорт XML-данных в существующую строку
-
В. Массовый импорт XML-данных из файла, содержащего DTD
-
Г. Указание признаков конца поля явным образом при помощи файла форматирования
-
Д. Массовый экспорт XML-данных
Источник: http://docs.microsoft.com/ru-ru/sql/relational-databases/import-export/examples-of-bulk-import-and-export-of-xml-documents-sql-server?view=sql-server-ver15
11 ответов
по состоянию на 2013 год…
единственный вариант экономии времени, на мой взгляд, для загрузки больших / огромных XML-файлов в SQL Server (как кто-то ранее кратко упоминал), чтобы использовать SQLXML 4.0 библиотека.
Это решение, которое я принял для загрузки огромных XML-файлов (7Гб в размере) на ежедневной основе. Предыдущий процесс, который использовал манипуляции C# в задаче скрипта, занял несколько часов. Использование sqlxml 4.0 занимает 15-20 минут. Как установить SQLXML 4.0. шаг за шагом!—15—>здесь. Для практических примеров в том, как это сделать end to end следуйте по этой ссылке MSDN.
мой XML также имеет вложенные элементы, поэтому он довольно сложный, в результате получается 10 таблиц с 2,5 до 4 миллионами строк каждая (ежедневный файл иногда больше 7 ГБ). Моя работа была основана исключительно на информации, которую я узнал из двух ссылок выше.
-
преимущества:
- быстро
- это Microsoft (http://www.microsoft.com/en-gb/download/details.aspx?id=30403)
- пакет SSIS будет очень упрощен
- вам не нужно тратить часы и часы, чтобы изменить пакет служб SSIS, если ваша схема XML изменяется. SQLXML может создавать таблицы в SQL Server для вас каждый раз при запуске пакета на основе об отношениях XSD, которые вы предоставляете.
-
недостатки
- создание XSD может занять некоторое время и требует некоторых знаний. Когда я сделал это, я узнал что-то новое, так что это не было настоящим недостатком для меня.
- видя, насколько прост пакет служб SSIS, ваш менеджер будет иметь впечатление, что вы не сделали никакой работы.
для просмотра больших файлов использовать Просмотр Больших Текстовых Файлов, милый маленький драгоценный камень.
Примечание: вопрос довольно старый, но «проблема» остается горячей. Я добавил этот пост для разработчиков, которые Google, как массовая загрузка XML-файлов в SSIS и земли здесь.
Я широко тестировал синтаксический анализатор MSSQL xml, bcp.exe утилита отлично работает для этого. Трюк придумывает правый Терминатор строки, так как это должно быть значение, которое не может возникнуть в вашем документе. Например, вы можете сделать следующее:
create table t1(x xml)
Ceate простой текстовый файл, содержащий только выбранный разделитель. Например, поместите эту строку в delim.txt:
-++++++++-
затем объедините это до конца экземпляра документа, из командной строки:
копировать myFile.xml + delim.txt вне.xml / b
после этого вы можете BCP его в базу данных, как:
bcp.тест ехе.dbo.Т1 из.в XML -Т-с-с — r -++++++++-
Если документ UTF-16, то замените переключатель-c на-w
первое, что я сделал, это получить первые X байтов (например, первый 1 МБ) XML-файлов, чтобы я мог взглянуть на них с помощью редактора по моему выбору.
Если у вас Cygwin установлен у вас уже есть хорошая утилита GNU, чтобы достичь этого:глава
head.exe -c1M comments.xml > comments_small.xml
кроме того, можно найти родной порт самой утилиты GNU здесь: http://unxutils.sourceforge.net/
для просмотра очень больших файлов, я нашел V просмотрщик файлов чтобы быть отличным.
Я использовал его для файлов размером до 8 ГБ. Для файлов с фиксированной длиной записи очень легко перемещаться по размеру блока, поскольку он основан на диске.
обратите внимание, что нет возможности редактирования.
сказав это, одна из трудностей с XML заключается в том, что это не очень хороший формат для больших «потоков», так как он имеет общее начало и конец структура и синтаксический анализатор, который не может держать весь файл в памяти, могут сделать некоторые довольно причудливые трюки, чтобы убедиться, что он соответствует DTD или схеме.
вы пробовали использовать OPENROWSET импортировать большие XML-файлы в таблицу SQL Server?
CREATE TABLE XmlTable( ID INT IDENTITY, XmlData XML)INSERT XmlTable(XmlData) SELECT * FROM OPENROWSET(BULK ‘(your path)xmldata.xml’, SINGLE_BLOB) AS X
поскольку у меня нет файлов 5GB под рукой, я не могу проверить это сам.
есть еще один способ решить эту проблему: потоковая передача Linq-to-Xml. Проверьте это блоге где Джеймс Ньютон-Кинг показывает, как читать XElement один за другим, и серия из двух частей здесь и здесь по той же теме командой Microsoft XML блог.
Марк
Источник: http://askdev.ru/q/import-xml-dannyh-v-ms-sql-server-programmnym-sposobom-367143/
2 ответа
Лучший ответ
Работа со значениями NULL — это нечто особенное в XML.
Определение значения NULL в XML: не существует . Так
<a> <b>hi</b> <c></c> <d/></a>
- <a> является корневым элементом.
- <b> — это элемент с узлом text().
- <c> — пустой элемент
- <d> является самозакрывающимся элементом
- <e> — хм — не там …
Важный совет: <c> и <d> одинаковы, абсолютно без разницы!
Вы можете запросить элемент с
.value(‘(/a/b)[1]’,’nvarchar(100)’)
И вы можете запросить узел text() специально
.value(‘(/a/b/text())[1]’,’nvarchar(100)’)
В этом вы найдете возможный ответ (немного скрытый): вы можете выполнять весь свой код без предиката проверки NULL, если вы запрашиваете узел text() специально.
Изменить это
ref.value(‘record[1][not(@xs:nil = «true»)]’ ,’varchar(100)’)
К этому
ref.value(‘(record[1]/text())[1]’ ,’varchar(100)’)
Что может нарушить это: если содержимое <record> может быть пустой строкой, вы получите NULL назад, а не ». Но это должно быть намного быстрее … Надеюсь, это нормально для вас …
Об эффективности: прочитайте этот ответ. Это покрывает вашу проблему довольно хорошо. Особенно часть, где время расходуется (перейдите по ссылкам в этом ответе).
1
Shnugo 10 Июл 2020 в 21:34
Просто чтобы дополнить ответ @Shnugo.
Вся заслуга ему.
Это ваш точный оператор SQL. Это должно дать вам около 20% улучшения производительности. Пожалуйста, дайте ему шанс.
;WITH XMLNAMESPACES (‘http://www.w3.org/2001/XMLSchema-instance’ as xs, DEFAULT ‘http://somenamespace.whatever.com/schemas/xmldata/1/’)INSERT INTO DataFromXml(Column1, Column2, Column3, Column4, Column5)SELECT ref.value(‘(record[1]/text())[1]’ ,’varchar(100)’) as Column1 ,ref.value(‘(record[2]/text())[1]’ ,’varchar(100)’) as Column2 ,ref.value(‘(record[3]/text())[1]’ ,’varchar(100)’) as Column3 ,ref.value(‘(record[4]/text())[1]’ ,’varchar(100)’) as Column4 ,ref.value(‘(record[5]/text())[1]’ ,’varchar(100)’) as Column5FROM @XML.nodes(‘/myxml/mydata/item’) xmlData(ref);
1
Yitzhak Khabinsky 10 Июл 2020 в 15:13
Источник: http://question-it.com/questions/469101/samyj-bystryj-sposob-importirovat-bolshoj-xml-v-tablitsu-sql-server
Introduction
A previous article I wrote on ‘DBA Skills for Developers’ gave a round up of various tips and tricks to make the life of a developer who had ‘inherited’ the task of in-house DBA hopefully a bit better. I was going to expand that article and add information on importing data to SQL server, but decided it is a topic and article that will grow over time so I decided to break it out on its on — and this is it.
Источник: http://codeproject.com/Articles/1073184/How-to-import-data-into-MS-SQL-server-from-CSV-and
Решение
Вы были на самом деле не очень далеко.
Чтобы получить атрибут, вы можете сделать это двумя способами:
- Доступ к нему, как если бы узел был массивом $node[‘attributeName’]
- Используйте метод с именем attribute (), и вы также можете сделать: $node->attributes()->attributeName;
Вот ваш код обновлен:
<?php$url =»http://query.yahooapis.com/v1/public/yql?q=select%20*%20from%20yahoo.finance.industry%20where%20id%20in%20(select%20industry.id%20from%20yahoo.finance.sectors)&env=store%3A%2F%2Fdatatables.org%2Falltableswithkeys»;$ch = curl_init();curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);curl_setopt($ch, CURLOPT_URL, $url); //getting url contents$data = curl_exec ($ch); //execule curl requestcurl_close($ch);$xml = simplexml_load_string($data);$con=mysql_connect(«localhost», «root», «»); //connect to servermysql_select_db(«symbol_list», $con) or die(mysql_error()); //select databaseforeach ($xml->results->industry as $industryNode){foreach ($industryNode->company as $companyNode){$industry = (string) $industryNode[‘name’];$company = (string) $companyNode[‘name’];$symbol = (string) $companyNode[‘symbol’];// perform sql query$sql = «INSERT INTO ‘symbols_xml’ (‘industry’, ‘company’, ‘symbol’)». «VALUES (‘$industry’, ‘$company’, ‘$symbol’)»;$result = mysql_query($sql);if (!$result){echo ‘MySQL ERROR’;}else{echo ‘SUCCESS’;}}}
2
Источник: http://web-answers.ru/php/import-xml-v-bazu-dannyh-mysql.html
Синтаксис оператора LOAD XML

Оператор LOAD XML считывает данные в таблицу из XML-файла;
file_name – имя файла в виде строки.
В дополнительном операторе ROWS IDENTIFIED BY tagname должен быть записан в виде литеральной строки и окружен угловыми скобками ( ).
Для записи данных из таблицы в XML-файл можно использовать следующую команду:

Для считывания файла назад в таблицу нужно использовать оператор LOAD XML INFILE.
Элемент – эквивалент строки таблицы БД.
Данный оператор поддерживает 3 разных формата XML:
-
Имена столбцов задаются через атрибуты и соответствующие им значения столбцов:
-
Имена столбцов задаются в виде тегов и значений столбцов как наполнения этих тегов:
-
Имена столбцов name в атрибуте :
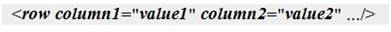

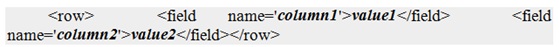
Данный формат используется другими инструментами MySQL (например, mysqldump).
Все форматы можно использовать в одном и том же XML-файле.
Пункт IGNORE number ROWS или IGNORE number LINES пропускает первый number строки в XML-файле.
Рассмотрим использование данного оператора на примере.
Пример 1
Предположим, что таблица создана следующим образом:

Предположим, что данная таблица пуста.
Далее предположим, что существует простой XML-файл person.xml, который содержит следующие данные:

Для импорта данных в person.xml в таблицу person можно воспользоваться следующим оператором:

Считается, что person.xml находится в каталоге данных MySQL.
В ситуации, когда файл не может быть найден, появится следующее сообщение об ошибке:

Пункт ROWS IDENTIFIED BY » ставит в соответствие каждый элемент в XML-файле строке таблицы, в которую импортируются данные. В данном примере это таблица person в базе данных test.
В результате будут импортированы 6 строк в таблицу test.person. Проверить результат можно с помощью простого оператора SELECT:

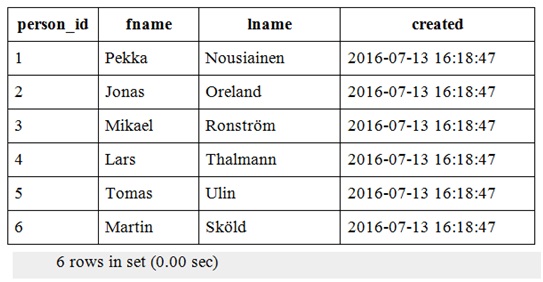
Данный пример показывает, как говорилось выше, что любые из трех разрешенных форматов XML могут находиться в одном и том же файле и считываться в операторе LOAD XML.
Для выполнения обратных действий, т.е. вывода табличных данных MySQL в XML-файл, можно, используя mysql клиент, выполнить следующие команды:

Опция —xml позволяет mysql клиенту использовать для вывода форматирование XML;
Опция –e заставляет клиент сразу после опции выполнить SQL-оператор.
С помощью пункта ROWS IDENTIFIED BY » можно импортировать данные из одного XML-файла в таблицу базы данных с разными определениями.
Пример 2
Предположим, что существует файл address.xml, содержащий следующий XML:

Можно снова воспользоваться таблицей test.person, очистить все существующие записи и показать ее структуру:

Далее создадим таблицу address в базе данных test при использовании оператора CREATE TABLE:

Для импорта данных из XML-файла в таблицу person выполним следующий оператор LOAD XML, определяющий строки в виде элементов :

Проверить импорта записей выполняется с помощью оператора SELECT:
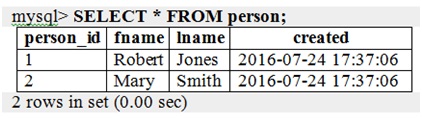
У элементов в XML-файле, начиная с , нет никаких соответствующих столбцов в таблице person , поэтому их пропускают.
Для импорта данных из элементов в таблицу address используем оператор LOAD XML, как показано на рисунке:

С помощью оператора SELECT можно проверить, были ли данные импортированы.
Данные из элемента не импортируется. Однако, столбец person_id в таблице address, значение атрибута person_id от родительского элемента для каждого импортируется в таблицу address.
Источник: http://spravochnick.ru/bazy_dannyh/yazyk_sql_osnovy_raboty_s_relyacionnymi_subd_osnovy_yazyka_sql/operator_load_xml_zagruzka_dannyh_v_bazu_iz_xml/
Другие решения
Других решений пока нет …
Источник: http://web-answers.ru/php/import-xml-v-bazu-dannyh-mysql.html
History
21 Jan 2016 — Version 1
10 Feb 2016 — Version 2 — added im/ex wizard
17 Feb 2016 — Version 3 — added Azure/cloud section, added section on advanced BCP im/ex
12 Apr 2016 — Version 4 — Updated code, added sample SQL download script
Источник: http://codeproject.com/Articles/1073184/How-to-import-data-into-MS-SQL-server-from-CSV-and