Как кодировать и расшифровывать с помощью шифра Виженера. Шифр Виженера — это метод шифровки, в котором используются различные «шифры Цезаря» на основе букв в ключевом слове. В шифре Цезаря каждую букву абзаца необходимо поменять местами с…
Советы
- Дважды перепроверьте, чтобы убедиться в правильности кодировки. Если вы неправильно закодируете текст, его невозможно будет правильно расшифровать, а понять, что в нем есть ошибка, без проверки очень сложно.
- Если использовать соответствующее программное обеспечение для графического программирования и тщательно все проверять, процесс можно автоматизировать.
- Если вы дадите кому-то зашифрованный текст, для расшифровки потребуется ключевое слово. Сообщите его человеку шепотом по секрету или зашифруйте с помощью шифра Цезаря. Имейте в виду, что на сегодняшний день этот шифр не является абсолютно надежным, и его можно взломать автоматически.
- В интернете есть средства расшифровки кода Виженера, которые вы можете найти и использовать.
- Если вы используете большой квадрат Виженера, включающий пунктуацию и пробелы, шифр будет сложнее расшифровать, особенно если ключевое слово или ключевая фраза имеют такую же или бо́льшую длину, чем сообщение.
- Еще один путь усложнить шифр — сначала зашифровать исходное сообщение другим способом (например, перестановочным шифром), а уже полученный результат закодировать с помощью шифра Виженера. Даже если шифр Виженера расшифруют, на выходе получится лишь бессмысленный набор букв. Не применяйте к исходному сообщению шифр Цезаря вместо перестановочного шифра, так как в этом случае оба шага шифрования можно будет объединить в один, и шифровка будет не очень надежной.
- Чем чаще ваше ключевое слово или фраза повторяются, тем легче расшифровать текст. Ключ должен быть как можно длиннее.
Источник: http://ru.wikihow.com/кодировать-и-расшифровывать-с-помощью-шифра-Виженера
Описание метода
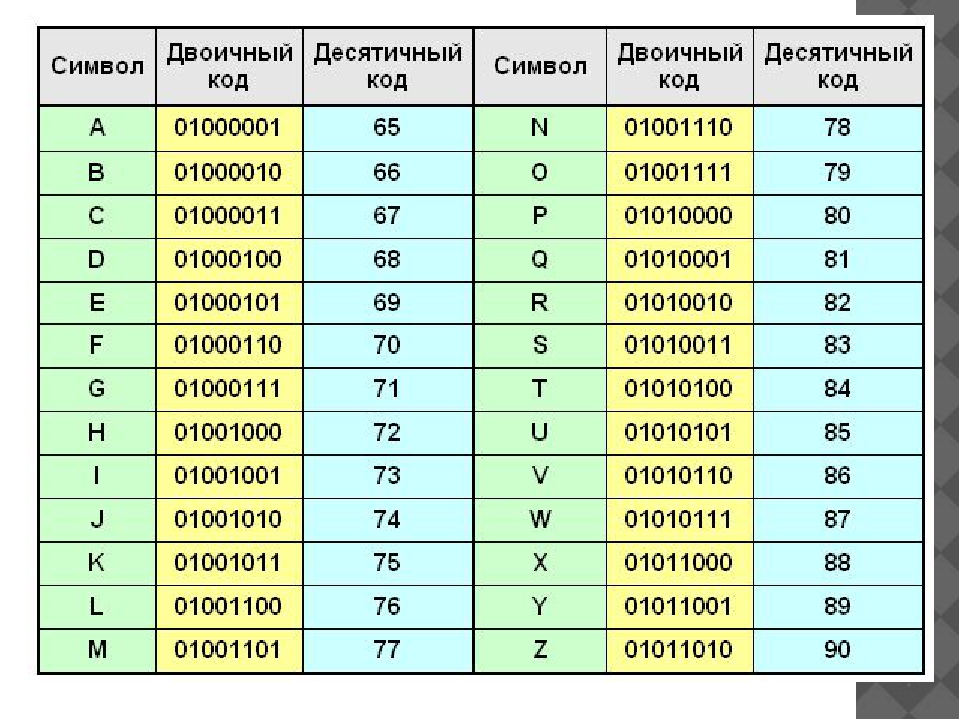
Шифр Вижнера включает последовательность нескольких шифров Цезаря. Для последнего характерен сдвиг на несколько строк. В целях шифрования можно использовать таблицу алфавитов, которая называется квадрат Виженера. В профессиональных кругах его именуют как tabula recta. Таблица Виженера состоит из нескольких строк по 26 символов. Каждая новая строка передвигается на определенное количество позиций. В итоге таблица содержит 26 различных шрифтов Цезаря. Каждый этап шифрования подразумевает использование различного алфавита, который выбирается в зависимости от символа ключевого слова.

Для того чтобы лучше понять суть данного метода, рассмотрим шифрование текста на примере слова ATTACKATDAWN. Лицо, которое посылает текст, записывает ключевое слово «LEMON» до того момента, пока оно не будет соответствовать длине переданного текста. Ключевое слово будет иметь вид LEMONLEMONLE. Первый символ заданного текста — А — зашифрован последовательностью L, являющейся первым символом ключа. Данный символ располагается на пересечении строки L и столбца A. Для следующего символа заданного текста применяется второй символ ключа. Поэтому второй символ закодированного текста будет иметь вид X. Он получился в результате пересечения строки E и столбца T. Другие части заданного текста шифруются аналогичным способом. В результате получается слово LXFOPVEFRNHR.
Источник: http://fb.ru/article/381590/shifr-vijenera-kvadrat-vijenera-shifrovanie-teksta
Нетекстовое сообщение
Если исходное сообщение не является фактическим текстом (например, имеет смысл английский текст) или у вас нет информации о его содержании, вам не повезло.
Особенно, если текст на самом деле хеширован или зашифрован дважды, то есть случайным образом.
Для взлома схемы шифрования требуется знание алгоритма и сообщений. Особенно в вашей ситуации вам нужно знать общую структуру ваших сообщений, чтобы ее нарушить.
Источник: http://stackru.com/questions/51434301/vzlomat-vizhenera-znaya-tolko-dlinu-klyucha
Предпосылки
В оставшейся части этого ответа позвольте мне предположить, что ваше сообщение на самом деле представляет собой простой английский текст. Обратите внимание, что вы легко можете перенять мой ответ на других языках. Или даже перенять методы для других форматов сообщений.
Позвольте мне также предположить, что вы говорите о классике Виженера (см. Википедию), а не об одном из его многочисленных вариантов. Это означает, что ваш ввод состоит только из буквA к Z, без регистра, без интерполяции, без пробелов. Пример:
MYNAMEISJOHN // Instead of: My name is John.
То же самое относится и к вашему ключу, он содержит только A к Z.
Затем классический Viginere сдвигается на смещение в алфавите по модулю размера алфавита (который равен 26).
Пример:
(G + L) % 26 = R
Источник: http://stackru.com/questions/51434301/vzlomat-vizhenera-znaya-tolko-dlinu-klyucha
Предупреждения
- Этот шифр ненадежен (как и любой другой), и его можно легко взломать. По современным стандартам шифр Виженера является очень ненадежным. Не используйте его для чего-либо действительно секретного. Для лучшей шифровки используйте AES и RSA. Однако этот шифр можно использовать с одноразовым ключом (случайная фраза такой же длины, как и текст, которая используется только раз) — если ключ хранить в секрете, расшифровка будет не такой простой.
Источник: http://ru.wikihow.com/кодировать-и-расшифровывать-с-помощью-шифра-Виженера
Словарь
Прежде чем говорить об атаках, нам нужно найти способ по сгенерированному ключу выяснить, действительно ли он правильный или нет.
Поскольку мы знаем, что сообщение состоит из английского текста, мы можем просто взять словарь (огромный список всех допустимых английских слов) и сравнить наше расшифрованное сообщение со словарем. Если ключ был неправильным, результирующее сообщение не будет содержать правильных слов (или будет содержать только несколько).
Это может быть немного сложно, поскольку нам не хватает интерполяции (в частности, пробелов).
N-граммы
Хорошо, что на самом деле существует очень точный способ измерения допустимости текста, который также решает проблему с отсутствующей вставкой.
Методика называется N-граммами (см. Википедию). Вы выбираете значение дляN, например 3(затем называемые триграммами) и начните разбивать текст на пары по 3 символа. Пример:
MYNAMEISJOHN // results in the trigrams:$$M, $$MY, MYN, YNA, NAM, AME, MEI, ISJ, SJO, JOH, OHN, HN$, N$$
Что вам сейчас нужно, так это частотный анализ наиболее распространенных триграмм в английском тексте. В Интернете существуют различные источники (или вы можете запустить его самостоятельно на большом текстовом корпусе).
Затем вы просто сравниваете свою трехграммовую частоту с частотой реального текста. Используя это, вы вычисляете оценку того, насколько ваша частота соответствует реальной частоте. Если ваше сообщение содержит много очень необычных триграмм, скорее всего, это ненужные данные, а не настоящий текст.
Небольшая заметка, монограммы (1 грамм) приводят к частоте одного символа (см. Википедия # Частота букв). Би-граммы (2 грамма) обычно используются для взлома Viginere и дают хорошие результаты.
Источник: http://stackru.com/questions/51434301/vzlomat-vizhenera-znaya-tolko-dlinu-klyucha
Об этой статье
Эту страницу просматривали 153 148 раз.
Источник: http://ru.wikihow.com/кодировать-и-расшифровывать-с-помощью-шифра-Виженера
Предупреждение к методу
Шифр Виженера, как и многие другие, не является надежным, поскольку его легко взломать. Если есть необходимость передать секретную информацию, не нужно прибегать к использованию данного метода. Для таких целей разработаны другие методы. Шифр Виженера является одним из самых старых и популярных методов шифрования.

В качестве ключа выступает специальная фраза. Она несколько раз повторяется и пишется над шифруемым текстом. В результате каждая буква посылаемого сообщения сдвигается относительно заданного текста на определенное число, которое задается буквой ключевой фразы. На протяжении нескольких веков данный метод устойчиво занимал позицию самого надежного метода шифрования. В 19 веке отмечены первые попытки взлома шифра Виженера, которые основывались на определении длины ключевой фразы. Если известна ее длина, то текст можно разбить на определенные фрагменты, которые кодируются одним и тем же сдвигом.
Источник: http://fb.ru/article/381590/shifr-vijenera-kvadrat-vijenera-shifrovanie-teksta
Атаки
Грубая сила
Первая и самая прямая атака — это всегда грубая сила. И, пока ключ и алфавит не такие уж большие, количество комбинаций относительно невелико.
Ваш ключ имеет длину 6, алфавит имеет размер 26. Таким образом, количество различных комбинаций клавиш6^26, который
170_581_728_179_578_208_256
Итак о 10^20. Это число может показаться огромным, но не забывайте, что процессоры уже работают в диапазоне гигагерц (10^9операций в секунду на ядро). Это означает, что одно ядро с частотой 1 ГГц позволит сгенерировать все решения примерно за 317 лет. Теперь замените это мощным процессором (или даже графическим процессором) и многоядерной машиной (есть кластеры с миллионами ядер), тогда это будет вычислено менее чем за день.
Но ладно, я понимаю, что у вас, скорее всего, нет доступа к такому хардкорному кластеру. Так что полный перебор невозможен.
Но не волнуйся. Есть простые приемы, чтобы ускорить это. Вам не нужно вычислять полный ключ. Как насчет того, чтобы ограничить себя первыми 3 символами вместо полных 6 символов. Тогда вы сможете расшифровать только подмножество текста, но этого достаточно, чтобы проанализировать, является ли результат действительным текстом или нет (используя словари и N-граммы, как упоминалось ранее).
Это небольшое изменение уже значительно сокращает время вычислений, поскольку тогда у вас есть только 3^26комбинации. Их создание занимает около 2 минут для одного ядра с частотой 1 ГГц.
Но вы можете сделать даже больше. Некоторые символы в английском тексте встречаются крайне редко, напримерZ. Вы можете просто начать с того, что не рассматриваете ключи, которые могли бы преобразовать эти значения в текст. Допустим, вы удалили этим 6 наименее распространенных символов, тогда ваши комбинации будут только3^20. Это занимает около 100 миллисекунд для одного ядра с частотой 1 ГГц. Да, миллисекунды. Этого достаточно для обычного ноутбука.
Частотная атака
Хватит грубой силы, давайте сделаем что-нибудь умное. Атака с использованием частотных букв — очень распространенная атака на эти схемы шифрования. Это просто, очень быстро и очень успешно. На самом деле, это настолько просто, что есть довольно много онлайн-инструментов, которые предлагают это бесплатно, например https://www.guballa.de/vigenere-solver (он может взломать ваш конкретный пример, я только что попробовал).
Хотя Viginere превращает сообщение в нечитаемый мусор, он не меняет распределение букв, по крайней мере, не по цифре ключа. Итак, если вы посмотрите, скажем, на вторую цифру вашего ключа, оттуда каждая шестая буква (длина ключа) в сообщении будет сдвинута точно на такое же смещение.
Давайте посмотрим на простой пример. КлючBAC и сообщение
CCC CCC CCC CCC CCC // rawDCF DCF DCF DCF DCF // decrypted
Как вы заметили, буквы повторяются. Глядя на третью букву, всегдаF. Это означает, что шестая и девятая буквы, которые такжеF, все должны быть одним и тем же исходным письмом. Поскольку они все были сдвинутыC от ключа.
Это очень важное наблюдение. Это означает, что частота букв в пределах кратной цифры ключа (k * (i + key_length)), сохранилась.
Давайте теперь посмотрим на распределение букв в английском тексте (из Википедии):

Все, что вам нужно сделать сейчас, это разбить ваше сообщение на блоки (по модулю длины ключа) и провести частотный анализ каждой цифры блоков.
Таким образом, для вашего конкретного ввода это дает блоки
BYOIZRLAUMYXXPFLPWBZLMLQPBJMSC…
Теперь вы анализируете частоту для цифры 1 каждого блока, затем цифру 2и так далее до цифры 6. Для первой цифры это буквы
B, L, X, B, P, …
Результат для вашего конкретного ввода:
[B=0.150, E=0.107, X=0.093, L=0.079, Q=0.079, P=0.071, K=0.064, I=0.050, O=0.050, R=0.043, F=0.036, J=0.036, A=0.029, S=0.029, Y=0.021, Z=0.021, C=0.014, T=0.014, D=0.007, V=0.007][L=0.129, O=0.100, H=0.093, A=0.079, V=0.071, Y=0.071, B=0.057, K=0.057, U=0.050, F=0.043, P=0.043, S=0.043, Z=0.043, D=0.029, W=0.029, N=0.021, C=0.014, I=0.014, J=0.007, T=0.007][W=0.157, Z=0.093, K=0.079, L=0.079, V=0.079, A=0.071, G=0.071, J=0.064, O=0.050, X=0.050, D=0.043, U=0.043, S=0.036, Q=0.021, E=0.014, F=0.014, N=0.014, M=0.007, T=0.007, Y=0.007][M=0.150, P=0.100, Q=0.100, I=0.079, B=0.071, Z=0.071, L=0.064, W=0.064, K=0.057, V=0.043, E=0.036, A=0.029, C=0.029, N=0.029, U=0.021, H=0.014, S=0.014, D=0.007, G=0.007, J=0.007, T=0.007][L=0.136, Y=0.100, A=0.086, O=0.086, P=0.086, U=0.086, H=0.064, K=0.057, V=0.050, Z=0.050, S=0.043, J=0.029, M=0.021, T=0.021, W=0.021, G=0.014, I=0.014, B=0.007, C=0.007, N=0.007, R=0.007, X=0.007][I=0.129, M=0.107, X=0.100, L=0.086, W=0.079, S=0.064, R=0.057, H=0.050, Q=0.050, K=0.043, E=0.036, C=0.029, T=0.029, V=0.029, F=0.021, J=0.021, P=0.021, G=0.014, Y=0.014, A=0.007, D=0.007, O=0.007]
Посмотри на это. Вы видите, что для первой цифры букваB очень часто, 15%. А затем письмоE с 10%и так далее. Есть большая вероятность, что письмоBдля первой цифры ключа является псевдонимом для E в реальном тексте (поскольку E является самой распространенной буквой в английском тексте) и что E обозначает вторую по распространенности букву, а именно T.
Используя это, вы можете легко вычислить обратную букву ключа, используемого для шифрования. Он получен
B — E % 26 = X
Обратите внимание, что распространение вашего сообщения может не соответствовать реальному распределению по всему английскому тексту. Особенно, если сообщение не такое длинное (чем длиннее, тем точнее вычисление распределения) или в основном состоит из странных и необычных слов.
Вы можете противостоять этому, попробовав несколько комбинаций из самых высоких в вашем распределении. Итак, для первой цифры вы можете попробовать,
B -> EE -> EX -> EL -> E
Или вместо сопоставления с E только, также попробуйте второй по распространенности персонаж T:
B -> TE -> TX -> TL -> T
Количество комбинаций, которые вы получаете с этим, очень мало. Используйте словари и N-граммы (как упоминалось ранее), чтобы проверить правильность ключа или нет.
Реализация Java
Ваше сообщение на самом деле очень интересно. Он идеально сочетается с реальной частотой букв в английском тексте. Таким образом, для вашего конкретного случая вам действительно не нужно пробовать какие-либо комбинации, и вам не нужно делать никаких проверок словаря / n-граммы. Фактически вы можете просто перевести наиболее распространенную букву в вашем зашифрованном сообщении (по цифре) в наиболее распространенный символ в английском тексте,Eи получите настоящий ключ.
Поскольку это так просто и тривиально, вот полная реализация на Java того, что я объяснял перед пошаговым описанием, с некоторыми выходными данными отладки (это быстрый прототип, не очень хорошо структурированный):
import java.util.*;import java.util.stream.Collectors;import java.util.stream.Stream;public final class CrackViginere { private static final int ALPHABET_SIZE = 26; private static final char FIRST_CHAR_IN_ALPHABET = ‘A’; public static void main(final String[] args) { String encrypted = «BYOIZRLAUMYXXPFLPWBZLMLQPBJMSCQOWVOIJPYPALXCWZLKXYVMKXEHLIILLYJMUGBVXBOIRUAVAEZAKBHXBDZQJLELZIKMKOWZPXBKOQALQOWKYIBKGNTCPAAKPWJHKIAPBHKBVTBULWJSOYWKAMLUOPLRQOWZLWRSLEHWABWBVXOLSKOIOFSZLQLYKMZXOBUSPRQVZQTXELOWYHPVXQGDEBWBARBCWZXYFAWAAMISWLPREPKULQLYQKHQBISKRXLOAUOIEHVIZOBKAHGMCZZMSSSLVPPQXUVAOIEHVZLTIPWLPRQOWIMJFYEIAMSLVQKWELDWCIEPEUVVBAZIUXBZKLPHKVKPLLXKJMWPFLVBLWPDGCSHIHQLVAKOWZSMCLXWYLFTSVKWELZMYWBSXKVYIKVWUSJVJMOIQOGCNLQVXBLWPHKAOIEHVIWTBHJMKSKAZMKEVVXBOITLVLPRDOGEOIOLQMZLXKDQUKBYWLBTLUZQTLLDKPLLXKZCUKRWGVOMPDGZKWXZANALBFOMYIXNGLZEKKVCYMKNLPLXBYJQIPBLNMUMKNGDLVQOWPLEOAZEOIKOWZZMJWDMZSRSMVJSSLJMKMQZWTMXLOAAOSTWABPJRSZMYJXJWPHHIVGSLHYFLPLVXFKWMXELXQYIFUZMYMKHTQSMQFLWYIXSAHLXEHLPPWIVNMHRAWJWAIZAAWUGLBDLWSPZAJSCYLOQALAYSEUXEBKNYSJIWQUKELJKYMQPUPLKOLOBVFBOWZHHSVUIAIZFFQJEIAZQUKPOWPHHRALMYIAAGPPQPLDNHFLBLPLVYBLVVQXUUIUFBHDEHCPHUGUM»; int keyLength = 6; char mostCommonCharOverall = ‘E’; // Blocks List<String> blocks = new ArrayList<>(); for (int startIndex = 0; startIndex < encrypted.length(); startIndex += keyLength) { int endIndex = Math.min(startIndex + keyLength, encrypted.length()); String block = encrypted.substring(startIndex, endIndex); blocks.add(block); } System.out.println(«Individual blocks are:»); blocks.forEach(System.out::println); // Frequency List<Map<Character, Integer>> digitToCounts = Stream.generate(HashMap<Character, Integer>::new) .limit(keyLength) .collect(Collectors.toList()); for (String block : blocks) { for (int i = 0; i < block.length(); i++) { char c = block.charAt(i); Map<Character, Integer> counts = digitToCounts.get(i); counts.compute(c, (character, count) -> count == null ? 1 : count + 1); } } List<List<CharacterFrequency>> digitToFrequencies = new ArrayList<>(); for (Map<Character, Integer> counts : digitToCounts) { int totalCharacterCount = counts.values() .stream() .mapToInt(Integer::intValue) .sum(); List<CharacterFrequency> frequencies = new ArrayList<>(); for (Map.Entry<Character, Integer> entry : counts.entrySet()) { double frequency = entry.getValue() / (double) totalCharacterCount; frequencies.add(new CharacterFrequency(entry.getKey(), frequency)); } Collections.sort(frequencies); digitToFrequencies.add(frequencies); } System.out.println(«Frequency distribution for each digit is:»); digitToFrequencies.forEach(System.out::println); // Guessing StringBuilder keyBuilder = new StringBuilder(); for (List<CharacterFrequency> frequencies : digitToFrequencies) { char mostFrequentChar = frequencies.get(0) .getCharacter(); int keyInt = mostFrequentChar — mostCommonCharOverall; keyInt = keyInt >= 0 ? keyInt : keyInt + ALPHABET_SIZE; char key = (char) (FIRST_CHAR_IN_ALPHABET + keyInt); keyBuilder.append(key); } String key = keyBuilder.toString(); System.out.println(«The guessed key is: » + key); System.out.println(«Decrypted message:»); System.out.println(decrypt(encrypted, key)); } private static String decrypt(String encryptedMessage, String key) { StringBuilder decryptBuilder = new StringBuilder(encryptedMessage.length()); int digit = 0; for (char encryptedChar : encryptedMessage.toCharArray()) { char keyForDigit = key.charAt(digit); int decryptedCharInt = encryptedChar — keyForDigit; decryptedCharInt = decryptedCharInt >= 0 ? decryptedCharInt : decryptedCharInt + ALPHABET_SIZE; char decryptedChar = (char) (decryptedCharInt + FIRST_CHAR_IN_ALPHABET); decryptBuilder.append(decryptedChar); digit = (digit + 1) % key.length(); } return decryptBuilder.toString(); } private static class CharacterFrequency implements Comparable<CharacterFrequency> { private final char character; private final double frequency; private CharacterFrequency(final char character, final double frequency) { this.character = character; this.frequency = frequency; } @Override public int compareTo(final CharacterFrequency o) { return -1 * Double.compare(frequency, o.frequency); } private char getCharacter() { return character; } private double getFrequency() { return frequency; } @Override public String toString() { return character + «=» + String.format(«%.3f», frequency); } }}
Источник: http://stackru.com/questions/51434301/vzlomat-vizhenera-znaya-tolko-dlinu-klyucha
Расшифровано
Используя приведенный выше код, ключ:
XHSIHE
И полное расшифрованное сообщение:
ERWASNOTCERTAINDISESTEEMSURELYTHENHEMIGHTHAVEREGARDEDTHATABHORRENCEOFTHEUNINTACTSTATEWHICHHEHADINHERITEDWITHTHECREEDOFMYSTICISMASATLEASTOPENTOCORRECTIONWHENTHERESULTWASDUETOTREACHERYAREMORSESTRUCKINTOHIMTHEWORDSOFIZZHUETTNEVERQUITESTILLEDINHISMEMORYCAMEBACKTOHIMHEHADASKEDIZZIFSHELOVEDHIMANDSHEHADREPLIEDINTHEAFFIRMATIVEDIDSHELOVEHIMMORETHANTESSDIDNOSHEHADREPLIEDTESSWOULDLAYDOWNHERLIFEFORHIMANDSHEHERSELFCOULDDONOMOREHETHOUGHTOFTESSASSHEHADAPPEAREDONTHEDAYOFTHEWEDDINGHOWHEREYESHADLINGEREDUPONHIMHOWSHEHADHUNGUPONHISWORDSASIFTHEYWEREAGODSANDDURINGTHETERRIBLEEVENINGOVERTHEHEARTHWHENHERSIMPLESOULUNCOVEREDITSELFTOHISHOWPITIFULHERFACEHADLOOKEDBYTHERAYSOFTHEFIREINHERINABILITYTOREALIZETHATHISLOVEANDPROTECTIONCOULDPOSSIBLYBEWITHDRAWNTHUSFROMBEINGHERCRITICHEGREWTOBEHERADVOCATECYNICALTHINGSHEHADUTTEREDTOHIMSELFABOUTHERBUTNOMANCANBEALWAYSACYNI
Это более или менее правильный английский текст:
er was not certain disesteem surely then he might have regarded thatabhorrence of the unintact state which he had inherited with the creedof my sticismas at least open to correction when the result was due totreachery are morse struck into him the words of izz huett never quitestill ed in his memory came back to him he had asked izz if she lovedhim and she had replied in the affirmative did she love him more thantess did no she had replied tess would lay down her life for him and sheherself could do no more he thought of tess as she had appeared on the dayof the wedding how here yes had lingered upon him how she had hung uponhis words as if they were a gods and during the terrible evening overthe hearth when her simple soul uncovered itself to his how pitiful herface had looked by the rays of the fire inherinability to realize thathis love and protection could possibly be withdrawn thus from being hercritiche grew to be her advocate cynical things he had uttered tohimself about her but noman can be always acyn I
Это, между прочим, цитата из британского романа » Тесс из д’Эрбервилей: чистая женщина, представленная добросовестно». Фаза шестая: обращение, глава XLIX.
Источник: http://stackru.com/questions/51434301/vzlomat-vizhenera-znaya-tolko-dlinu-klyucha
Проведение анализа частоты
Если результат процесса дешифровки оказался положительным, можно вписывать текст в столбцы. Столбцы формируются на базе исходного текста. Касицкий изобрел наиболее усовершенствованную форму текста. Однако средства данного метода невозможно применять в том случае, если решетка уходит от стандартной последовательности букв в алфавите. Поэтому данный метод позволяет узнать длину ключей лишь в частных случаях.
Источник: http://fb.ru/article/381590/shifr-vijenera-kvadrat-vijenera-shifrovanie-teksta